Using Multi-Dimensional Blocking
The PVFS multi-dimensional block interface (MDBI) provides a slightly higher-level view of file data than the native PVFS interface. With the MDBI, file data is considered as an N dimensional array of records. This array is divided into "blocks'' of records by specifying the dimensions of the array and the size of the blocks in each dimension. The parameters used to describe the array are as follows:
| D - number of dimensions |
| rs - record size |
| nbn - number of blocks (in each dimension) |
| nen - number of elements in a block (in each dimension) |
| bfn - blocking factor (in each dimension), described later |
There are five basic calls used for accessing files with MDBI:
int open_blk(char *path, int flags, int mode); int set_blk(int fd, int D, int rs, int ne1, int nb1, ..., int nen, int nbb); int read_blk(int fd, char *buf, int index1, ..., int indexn); int write_blk(int fd, char *buf, int index1, ..., int indexn); int close_blk(int fd); |
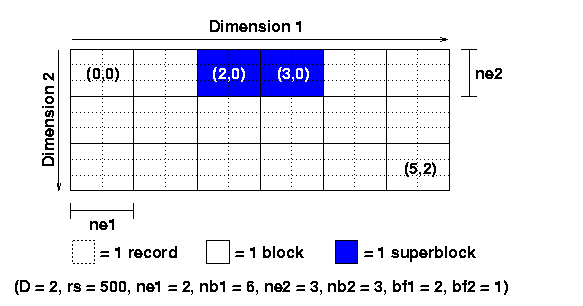
In this example, the array would be described with a call to set_blk() as follows:
set_blk(fd, 2, 500, 2, 6, 3, 3); |
read_blk(fd, &buf, 2, 0); |
write_blk(fd, &blk, 5, 2); |
Since it is difficult to predict what blocks should be accessed when ahead of time, PVFS relies on user cues to determine what to buffer. This is done by defining "blocking factors'' which group blocks together. A single function is used to define the blocking factor:
int buf_blk(int fd, int bf1, ..., int bfn); |
Looking at Figure 5 again, we can see how blocking factors can be defined. In the example, the call:
buf_blk(fd, 2, 1); |
Whenever a block is accessed, if its superblock is not in the buffer, the current superblock is written back to disk (if dirty) and the new superblock is read in its place — then the desired block is copied into the given buffer. The default blocking factor for all dimensions is 1, and any time the blocking factor is changed the buffer is written back to disk if dirty.
It is important to understand that no cache coherency is performed here; if application tasks are sharing superblocks, unexpected results will occur. It is up to the user to ensure that this does not happen. A good strategy for buffering is to develop your program without buffering turned on, and then enable it later in order to improve performance.