Heracles Architecture - Multi-Core
Cluster
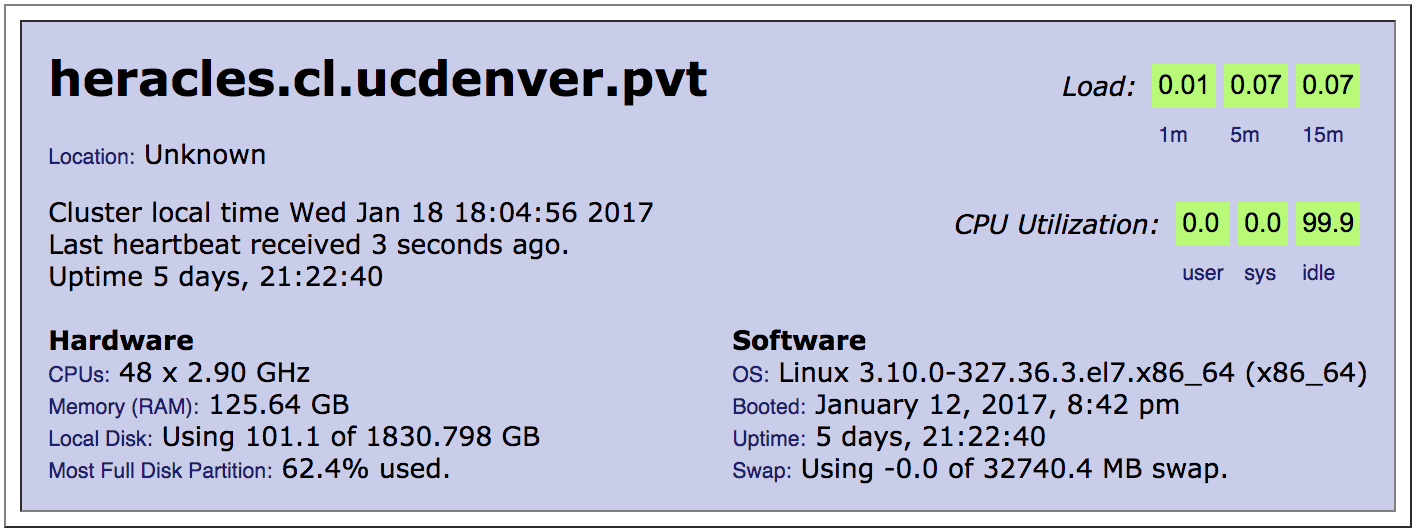
Server name: heracles.ucdenver.pvt
Heracles Multi-core cluster consists of following primary components:
- Total of 18 nodes distributed as
- 1 master node
- 16 compute nodes
- 1 node with 4 x NVIDIA Tesla P100 GPUs
- Mellanox SwitchX-2 18-Port QSFP FDR Externally Managed Switch (1U)
- Non-Blocking Switch Capacity of 2Tb/s
- 16GB DDR4 2.4GHZ and 128GB SSD per node
- L1d cache: 32K
- L1i cache: 32K
- L2 cache: 256K
- L3 cache: 30MB
- 2 x Intel Xeon E5-2650v4 Processors with 24 cores (12 cores per Processor)
- Intel C612 chipset
- Intel QuickPath Interconnect (QPI) with system bus up to 9.6GT/s
- 128GB DDR4 2400 MHz ECC/Registered Memory
- 30MB L3 Cache, DDR4-2400, 9.6 GT/sec QPI, 105W
- Supports Hyper-Threading
- HGST SN100 1.6TB NVMe 2.5" Solid State Drive for Ultra-Fast Scratch Space
- Each node has 2 x Intel Xeon E5-2650v4 Broadwell-EP 2.20 GHz Twelve Cores
- Supports Hyper-Threading, i.e., each core can run two
threads that gives a total of 48 threads per node (2 processors x 12
cores per processor x 2 threads per core)
- 30MB L3 Cache, DDR4-2400, 9.6 GT/sec QPI, 105W
- 128GB Total Memory per Node @ 2400MHz
- 120GB Intel DC S3510 2.5" SATA 6Gbps MLC SSD (16nm) per node
- SATA 6Gb/s Interface (Supports 3Gb/s)
- 384 cores (16 nodes x 2 processors per node x 12 cores per processor)
- They can run 768 threads (384 cores x 2 hyperthreads per core)
- 4 x NVIDIA Tesla P100 16GB "Pascal" SXM2 GPU Accelerator
- 3584 cuda cores per GPU
- Total of 14,336 cuda cores
- 2 x Intel Xeon E5-2650v4 Broadwell-EP 2.20 GHz Twelve Cores
- 30MB L3 Cache, DDR4-2400, 9.6 GT/sec QPI, 105W
- Supports Hyper-Threading and Turbo Boost up to 2.9 GHz
- NVIDIA Tesla P100 16GB "Pascal" SXM2 GPU Accelerator
- SXM2 form factor with NVLink interconnect support
- GP100 GPU chip with NVIDIA-certified Passive Heatsink
- 3584 CUDA Cores with Unified Memory and Page Migration Engine
- 16GB High-Bandwidth HBM2 Memory (720 GB/sec peak bandwidth)
- IEEE Half-, Single-, and Double-Precision Floating Point
- Performance (with GPU Boost): 21.2 TFLOPS (half), 10.6 TFLOPS (single), 5.3 TFLOPS (double)
- ssh node18 /usr/bin/nvidia-smi
Each node in the cluster has 2 x Intel Xeon E5-2650v4 Processors with 24 cores (12 cores per Processor)
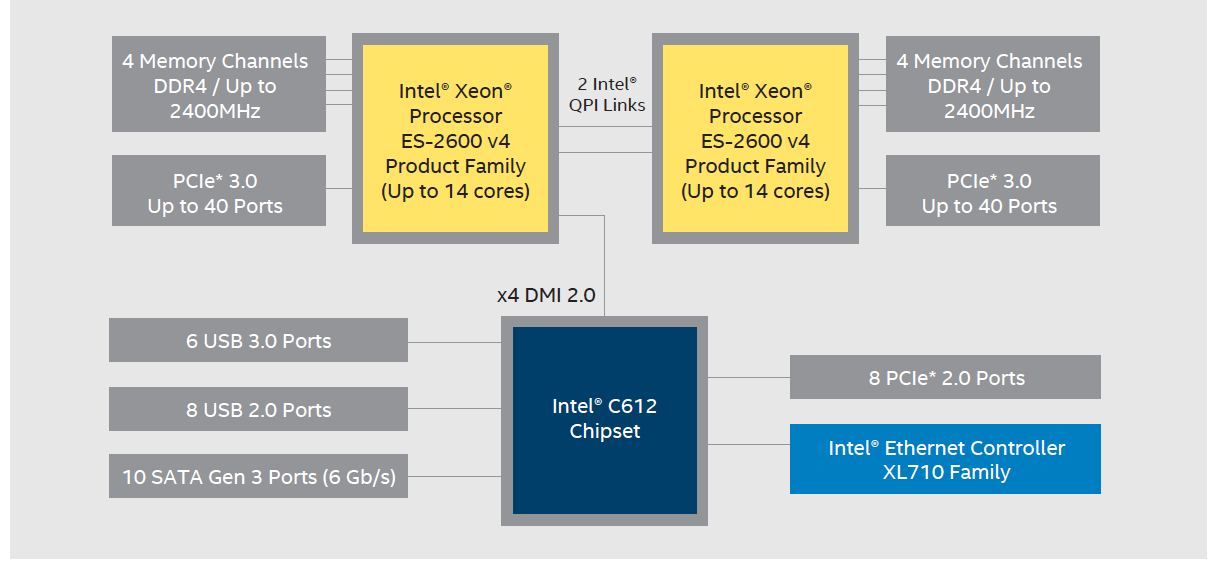
Figure 2. Intel Xeon Processor E5-2600 v4 Product Family
Cache Hierarchy
Master Node - node 1
The master node is mainly used to manage all computing resources and
operations on Heracles cluster and it corresponds to node 1 in the
cluster. It is also the machine that users log into,
create/edit/compile programs, and submit the programs for execution on compute nodes. Users do not run their programs on master node. Repeat: user programs MUST NOT be run on master node. Instead, they have to be submitted to the compute nodes for execution.
The master node on Heracles cluster is featured by:
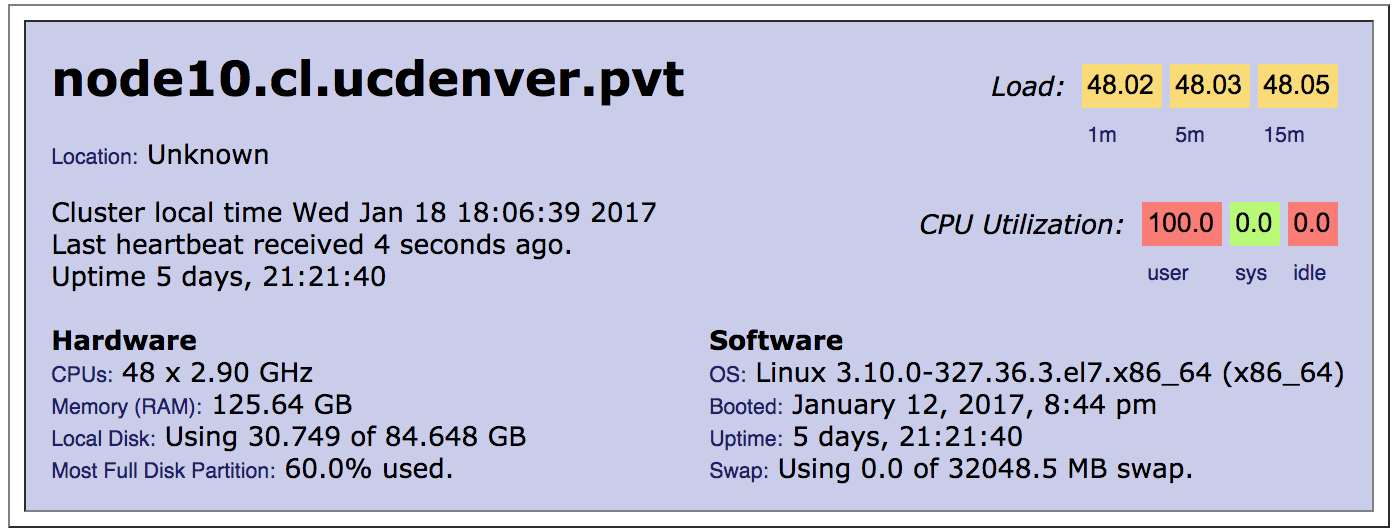
Compute Nodes - node 2 to node 17
Compute nodes execute the jobs submitted by users. From
the master node, users may submit programs to execute them on one or more
compute nodes.There are 16 compute nodes (nodes 2 to 17) on Heracles.
We have 4 x NumberSmasher-4X Intel Xeon Twin Servers, that containg four compute nodes each one, in a total of 16 compute nodes.
Node 18 with 4 x Nvidia Tesla P100

Each Nvidia Tesla P100-SXM2-16GB has the following Features:

Each Nvidia Tesla P100-SXM2-16GB has the following Capacity
| CUDA Driver Version / Runtime Version |
8.0 / 8.0 |
| CUDA Capability Major/Minor version number |
6.0 |
| Total amount of global memory: |
16276 MBytes (17066885120 bytes) |
| (56) Multiprocessors, ( 64) CUDA Cores/MP |
3584 CUDA Cores |
| GPU Max Clock rate |
405 MHz (0.41 GHz) |
| Memory Clock rate |
715 Mhz |
| L2 Cache Size: |
4194304 bytes |
| Total amount of constant memory: |
65536 bytes |
| Total amount of shared memory per block: |
49152 bytes |
| Total number of registers available per block: |
65536 |
| Warp size |
32 |
| Maximum number of threads per multiprocessor |
2048 |
| Maximum number of threads per block: |
1024 |
| Max dimension size of a thread block (x,y,z) |
(1024, 1024, 64) |
| Max dimension size of a grid size (x,y,z) |
(2147483647, 65535, 65535) |
| Concurrent copy and kernel execution |
Yes with 2 copy engine(s) |
You can monitor the GPUs on node 18 by using this command:


